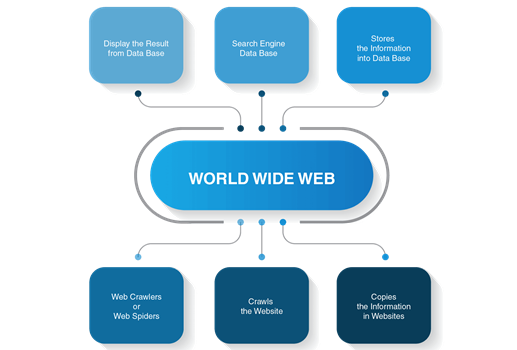
A web crawler, often known as a spider, is a sort of bot that is commonly used by search engines such as Google and Bing. Their goal is to index the data of websites from all over the Internet so that they can be displayed in search engine results. So, what is a bot? It is a software platform that has been designed to do certain activities. Bots are autonomous, which means they operate according to their commands without the requirement for a human operator to set them up each time. Bots frequently mimic or try replacing the actions of human users. They often do routine tasks at a significantly faster rate than human operators. We could usually find bots employ on the network. These can be used to scan content, perform some specialized actions over the networks, or interact with users. Some bots are used as search engine bots to assist the users in their searches whereas some can be used for cyberattacks like conveying spam, or any other of the same kind. We are here to learn about the bots that are used in search engine which is also known as web crawlers.
{kind=link}
These bots are analogous to someone going through all the volumes in a disorderly library and compiling a card catalog so that those visiting the library can quickly and easily locate the data they require. The organizers will study the header, synopsis, and part of the main content of each book to find out what it’s about in order to help classify and sort the library’s volumes by topic.
Search Indexing
After the brief discussion about the bots and the web, crawlers let us know what exactly is search indexing. The term search indexing means simple as the name suggests. It is like a catalog made specifically for the internet, so the search engine would know exactly where to get the information related to the topic user is searching for. It may also be likened to a book’s index, which lists all the locations throughout the book when a specific topic or term is addressed.
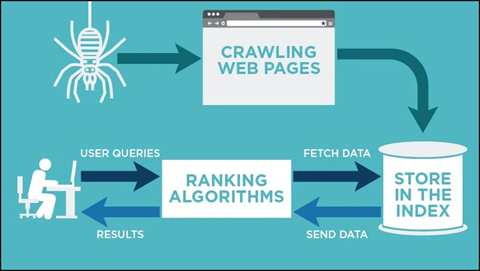
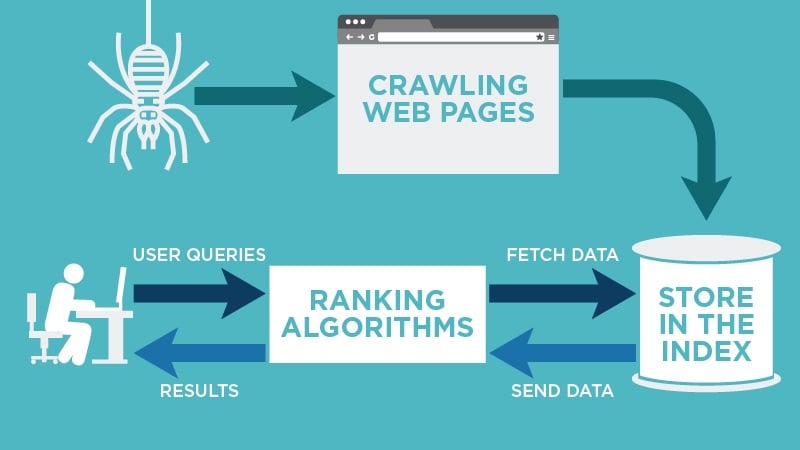
Fig. Link: https://neilpatel.com/wp-content/uploads/2018/03/crawling-web-pages.jpg
{kind=link}
Indexing is primarily concerned with the text displays on the page, as well as the metadata about the page that visitors do not see. Apart from a few specific terms, while most search engines index an internet site, they index all of the terms on the pages. When individuals look for certain terms, the search engine searches the index and presents the most factual information.
Working of the Web Crawlers
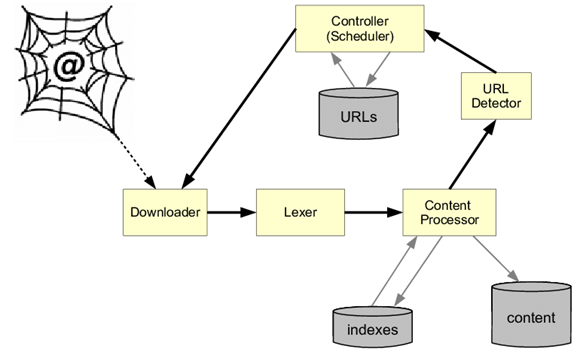
Every second there is something new added to the already vast internet. Since practically it is impossible to determine the actual number of web pages present on the internet these spiders begin with a list of known URLs. While they are crawling on the known web pages, they get access to many other hyperlinks of other pages and these hyperlinks are then added to the list to let the spiders know where to crawl next. With the boundless internet this process of indexing can go on forever. That is why web crawlers are made to follow some precise approach to limit them with the pages they are to crawl, the order and how many times those web pages are to be crawled is also determined using the precise approach.
{kind=link}
Often these web crawlers do not and are often not meant to crawl the complete publicly released Internet; rather, they choose which pages to crawl first depending on the number of those other pages that link to that page, the website traffic that page receives, and other aspects that indicate the page’s possibility of containing crucial data. That simply means the website that is mentioned often on other websites must contain some high-quality crucial data. That is why it is crucial to be indexed. Web crawlers are designed to revisit the web pages it crawled once as the internet always keeps changing. The data on the webpage is constantly modified. So, the index should also be modified according to the data. The robots.txt protocol, also known as r(obots) e(xclusion) p(rotocol), is also used by web crawlers to determine which pages to crawl. They will examine the robots.txt file held by the page’s web server prior to actually crawling it. A robots.txt file is a text file that sets the rules for any bots that wish to access the housed website or application. These rules specify which pages the bots can crawl or which links they can click on. Even when the end goal is the same the web crawlers from various search engines act slightly differently because of the trademarked algorithms that are built by the search engines into the web crawlers.
Do you know from where does the ‘WWW’ in the URLs come from? The internet is also named W(orld) W(ide) W(eb). Web Crawlers have an interesting name that happens to be spiders. The reason for this is that the web crawlers are always found crawling all over the internet just like the actual spiders all over the spiderwebs.
Must we allow spiders to access the web?
Web crawlers demand resources to index material, they make requests to the server that the server must reply to, much like a person visiting a website or other bots exploring a website. Depending on the quantity of material on each page or the number of pages on the site, it may be in the website operator’s mutual benefit not to enable search indexing too frequently, since excessive indexing may overburden the server, generate higher bandwidth costs, or perhaps both.
Effects of Web crawlers on SEO:
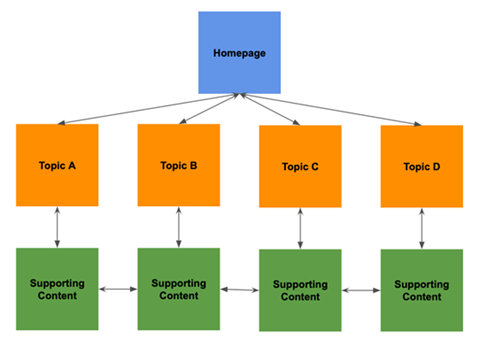
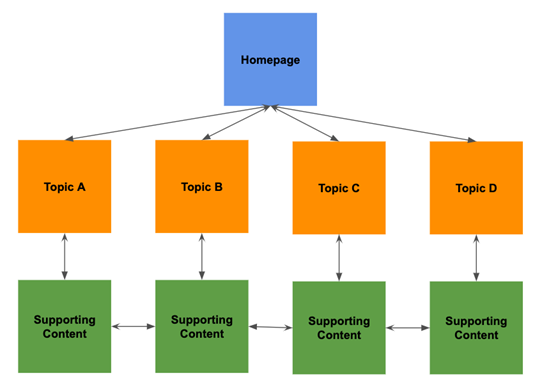{kind=link}
S(earch) e(ngine) o(ptimization) is the technique of preparing material for search indexing in order for a website to appear higher in search results. If spider bots do not crawl a website, it cannot be indexed and will not appear in search results. As a result, if a website owner wishes to obtain organic search results, they must not restrict web crawler bots.
The bots have a lot of advantages but it does not only give advantage with its presence. Malfunctioning bots can do considerable damage to any sever. It can be poor experience or server crash or even worse data theft by some hacker.
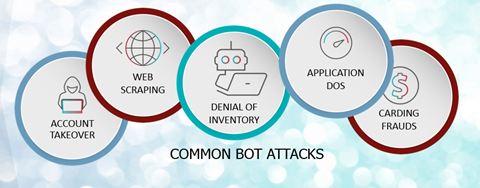
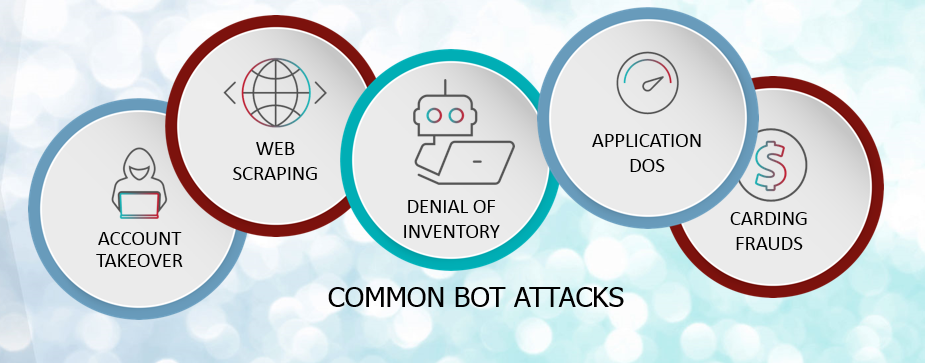
Fig. Link: https://blog.radware.com/wp-content/uploads/2019/03/common-bot-attacks.png
{kind=link}
That is why bot management is one crucial topic that must consider web crawling so the web crawlers are not blocked along with the malicious or malfunctioning bots.