

A supercomputer is nothing but a computer with some high level of performance when compared to a computer used for general purposes. The performance of the supercomputer is usually measured in the form of floating-point operations per second also known as FLOPS, instead of giving a million instructions per second (MIPS). Since 2017, there have been a few supercomputers which have existed which can perform over a hundred quadrillion FLOPS.
Since November 2017, all of the world’s fastest 500 supercomputers ran on Linux-based operating systems. Additional research is being funded and conducted in the United States, the European Union, Taiwan, Japan, and also in China to build a faster, more powerful, and technologically superior supercomputers.
We should know that, supercomputers play a vital role in the field of computational science, and are also being used for a wide range of computationally tasks in various fields, including quantum mechanics, weather forecasting, climate research, oil and also in gas exploration, molecular modelling (computing the structures and properties of chemical compounds, biological macromolecules, polymers, and crystals), and physical simulations (such as simulations of the early moments of the universe, airplane , the detonation of nuclear weapons, and also nuclear fusion). They prove to be essential in the field of cryptanalysis as well.
Supercomputers have been introduced in the 1960s, and for several decades the fastest were made by Seymour Cray at Control Data Corporation, Cray Research and subsequent companies bearing his name or the same monogram. The first such made machines were highly tuned conventional designs that runs more faster than their general-purpose computers. Throughout the entire decade, increasing amounts of parallelism kept on adding, with one to four processors being typical in nature and performance. In the year 1970, vector processors operating on a wide arrays of data came to the domination. A notable example is the highly successful Cray-1 of 1976. Vector computers remained the dominant design up until the 1990s. From then until today, massively parallel supercomputers with tens of thousands of processors have become the norm.

Energy usage and heat management:
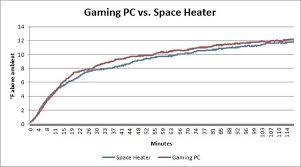
Throughout the decades when supercomputers have been in use, the management of heat density has remained a key issue for most of them. The more amount of heat generated by a system may also have other effects such as reducing the lifetime of other system components. There have been diverse approaches to contain this heat management, from pumping Fluorinert throughout the entire system to a hybrid liquid-air cooling system or air cooling with normal air conditioning temperatures. A supercomputer consumes more amount of electrical power, almost all of which is converted into the heat, which in-turn requires cooling. The cost to power and cool the super computer can be significant which is around $400 an hour or about $3.5 million per year.
Heat management is a major issue in the complex electronic devices and affects powerful computer in numerous ways. The thermal design power and CPU power dissipation issues in supercomputing by far exceeds those of traditional computer cooling technologies.
The packing of thousands of processors together generates huge amount of heat density which needs to be dealt with. The Cray-2 was liquid cooled and also used a Fluorinert “cooling waterfall” which was forced through the modules under pressure.
Operating systems:
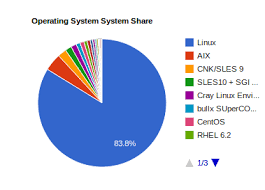
Operating systems which are required by the super computers have undergone major transformations, based on the changes in the architecture of the super computer. While early operating systems were custom tailored to each supercomputer to gain speed, the trend has been to move away from built in operating systems to the adaptation of more generic software such as Linux.
Since the modern massively parallel supercomputers typically separate the computations from other services by using multiple nodes, they usually run different operating systems based on different nodes such as using a small and efficient lightweight kernel such as CNK or CNL on compute nodes, but a larger system such as a Linux-derivative on server and I/O nodes.
While in a traditional multi-user computer system job scheduling is, in effect, a tasking problem for processing and peripheral resources, in a massively parallel system, the job management system needs to manage the allocation of both computational and communication resources, as well as gracefully deal with inevitable hardware failures when tens of thousands of processors are present.[84]
Although most modern supercomputers use Linux-based operating systems, each manufacturer has its own specific Linux-derivative, and no industry standard exists, partly due to the fact that the differences in hardware architectures require changes to optimize the operating system to each hardware design
Computing clouds:

Cloud computing with its recent and rapid expansions and development have grabbed the attention of high-performance computing (HPC) users and developers in recent years. Cloud computing attempts to provide HPC-as-a-service exactly like other forms of services available in the cloud such as software as a service, platform as a service, and infrastructure as a service. HPC users may benefit from the cloud in different angles such as scalability, resources being on-demand, fast, and inexpensive. On the other hand, moving HPC applications have a set of challenges too. Good examples of such challenges are virtualization overhead in the cloud, multi-tenancy of resources, and network latency issues. Much research is currently being done to overcome these challenges and make HPC in the cloud a more realistic possibility.
In 2016, Penguin Computing, Parallel Works, R-HPC, Amazon Web Services, Silicon Graphics International, Rescale, and Gomput started to offer HPC cloud computing. The Penguin On Demand (POD) cloud is a bare-metal compute model to execute code, but each user is given virtualized login node. POD computing nodes are connected via non-virtualized 10 Gbit/s Ethernet or QDR InfiniBand networks.
Amazon’s Elastic Compute Cloud and Penguin Computing argues that virtualization of computing nodes is not preferable for HPC. Penguin Computing has also criticized that HPC clouds may have allocated computing nodes to customers that are far apart, causing latency which in-turn impairs the performance for some HPC applications.
I would like to conclude by saying, the need for super computer’s is increasing with the rapidly evolving technologies and we need to ensure that it is being put to good use.