What Does Cluster Analysis Mean?
Cluster analysis is a statistical classification technique that groups together items or points that have similar features into clusters. It refers to a variety of techniques and strategies for classifying items into groups of comparable types. Cluster analysis aims to organise observable data into meaningful structures so that more insight can be gained. IT is the process of grouping data sets into a specified number of clusters with similar features among the data points inside each cluster. Clusters are made up of data points that are grouped together in such a way that the space between them is kept to a minimum. To put it another way, clusters are areas with a high density of related data points. It’s typically used to analyse a data set, locate interesting data among large data sets, and draw conclusions from it. The clusters are usually observed in a spherical shape, however this isn’t required; the clusters can be any shape.

The way the clusters are produced is determined by the type of algorithm we choose. Because there is no criterion for good clustering, the conclusions that must be drawn from the data sets are also dependent on the user. Without our knowledge, cluster analysis is frequently applied to relatively simple things like food groups in the grocery store or a group of people eating together in a restaurant. Foods are grouped in the grocery store according to their type, such as beverages, meat, and fruit; we can already see patterns in such groups.
Why to use cluster analysis?
Cluster analysis is used to uncover natural groupings of patterns, points, or objects. Clustering can be described as a pattern of resemblance between classes with low intraclass variation and significant interclass variation. The shape, size, and density of clusters vary. Cluster detection gets significantly more challenging when there is noise in the data. “An ideal cluster can be described as a compact and isolated group of points.” In actuality, cluster interpretation necessitates domain knowledge. Even while people can find clusters in two and three dimensions, high-dimensional data necessitates the use of algorithms. It is a common statistical data processing approach used in a variety of domains, including machine learning, pattern recognition, image analysis, knowledge retrieval, bioinformatics, data compression, and computer graphics, among others. Clustering and classification are both used to segment the data. Unlike classification, clustering models divide data into classes that haven’t been specified yet. Data is segmented in classification models by allocating it to classes that have been previously defined and described in a goal.
Different types of cluster:
Clustering can be divided into two categories: hard clustering and soft clustering. One data point can only belong to one cluster in hard clustering. In soft clustering, however, the result is a probability likelihood of a data point belonging to each of the pre-defined groups. I.e. in hard clustering, each data point is either totally or partially associated with a cluster and in soft clustering, instead of assigning each data point to a separate cluster, soft clustering assigns a chance or likelihood of that data point being in those clusters.
Different Models of cluster:
- K-means cluster model: One of the most extensively used algorithms is k-means clustering. Based on the distance metric used for clustering, it divides the data points into k clusters. The user is responsible for determining the value of ‘k.’ The distance between the data points and the cluster centroids is determined. The cluster is awarded to the data point that is closest to the cluster’s centroid. It computes the centroids of those clusters again after each iteration, and the procedure repeats until a pre-determined number of iterations have been finished or the centroids of the clusters have not changed after each iteration.
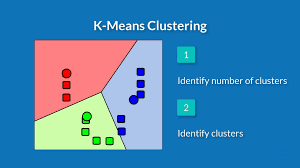
- Centroid models: Centroid models are iterative clustering techniques in which the notion of similarity is generated from a data point’s proximity to the cluster’s centroid. The K-Means clustering algorithm is a common example of this type of technique. The number of clusters required at the end of these models must be specified beforehand, which necessitates prior knowledge of the dataset. The local optima are found by running these models iteratively.
- Models of distribution: These clustering models are founded on the premise that all data points in a cluster are likely to belong to the same distribution (For example: Normal, Gaussian). Overfitting is a common problem with these models. The Expectation-maximization algorithm, which uses multivariate normal distributions, is a common example of these models.
- Hierarchical clustering model: Based on distance measurements, Hierarchical Clustering groups (Agglomerative or also known as Bottom-Up Approach) or divides (Divisive or also known as Top-Down Approach) the clusters. Each data point in agglomerative clustering functions as a cluster at first, and then the clusters are grouped one by one. The antithesis of Agglomerative, Divisive starts with all of the points in one cluster and splits them to make other clusters. These algorithms generate a distance matrix for all existing clusters and link them together based on the linkage criteria. A dendrogram is used to show the clustering of data points.
- Fuzzy clustering model: The assignment of data points to any of the groups in fuzzy clustering is not important. A data point can be assigned to multiple clusters in this case. It returns the probability of each data point belonging to one of the clusters as the result. Fuzzy c-means clustering is an example of a fuzzy clustering algorithm. The procedure is similar to K-Means clustering, but the parameters used in the computation, such as the fuzzifier and membership values, are different.
- Connectivity models: As the name implies, these models are founded on the idea that data points closer together in data space are more comparable than data points further apart. These models can go one of two paths. They begin by classifying all data points into discrete clusters and then aggregating them when the distance between them diminishes in the first strategy. The second method classifies all data points into a single cluster, which is subsequently partitioned when the distance between them grows. Furthermore, the choice of distance function is a personal one. These models are simple to understand, but they lack the scalability needed to handle large datasets.
- Density Models: These models look for areas in the data space with varying densities of data points. It isolates distinct density regions and groups the data points inside these regions into clusters. DBSCAN and OPTICS are two popular density models.
Clustering tools:
There are many tools used in the process of clustering some of them are,
- Clustanfraphics3
- CMSR Data Miner
- IBM SPSS Modeler
- NeuroXL Clusterizer
- perSiimplex
- Visipoint
- TeeChart
These tools, as well as many more related to computer equipment, can be found on the website of “X-TECH BUY,” one of Melbourne’s most popular purchasing websites. This website, https://www.xtechbuy.com/, sells a variety of software and hardware security products, including AIDA64 and others.
![]()
Conclusion:
We have seen an overview in this blog of the clustering processes and the various clustering methods with their examples. This article was meant to help you begin clustering. These clustering methods have their own advantages and disadvantages that limit them to only certain data sets. It’s not just the algorithm but there are many other factors such as machine hardware, algorithm complexity, etc., which come into the picture when analysing the data package. Problems may occur at any point in the network, if we feel stuck any point, you can get in touch with “Computer Repair Onsite ” You’ll have a much better chance of quickly fixing the issue with their team of “Computer Repair Onsite (CROS)”by clicking here .

Now you must decide which algorithm to use and which will deliver better results in specific scenarios. In any machine learning task, a one-size-fits-all technique does not work. So, continue to experiment and get your hands filthy in the world of clustering. However, if you are having difficulty making judgments or employing data cluster analysis, there is an experienced team right here for us, namely “BENCHMARK IT SERVICES,” where we can receive all the solutions to our difficulties, whether it is a large business problem or a single data problem.
![]()